


Research|Is the AI Compute Demand Scaling Law Dead?
o1, post-training, synthetic data, Nvidia moat, supply-demand, etc.

The rapid evolution of artificial intelligence (AI) models has led to an unprecedented surge in computational demands, challenging the capacities of even the most advanced tech infrastructures. Industry leaders like Microsoft and OpenAI are experiencing overwhelming demand for AI services, often surpassing their current computational resources. Microsoft's CEO, Satya Nadella, noted that Azure's OpenAI service usage has more than doubled in the past six months, with AI business expected to reach an annual revenue run rate of $10 billion by the second quarter, marking it the fastest-growing business in Microsoft's history. Similarly, OpenAI's CEO, Sam Altman, acknowledged that a lack of compute capacity is delaying the release of the company's products. This escalating demand underscores the critical need for scalable, efficient computing solutions to support the next generation of AI advancements.
However, there are several recent debate on whether the scaling law has ended and we’ve reached the plateau of AGI, e.g., the information’s recent articles on o1 and reasoning. However, those articles lack in-depth discussion in the technology behind it. To fully understand the GPU demand, we need to understand how the reasoning AI models are evolving and how that will affect Nvidia’s moat.
O1: shifting from pretraining to pretraining + post-training + inference
o1 employs reinforcement learning and synthetic data to enhance the reasoning abilities of large models, enabling the models to learn deep thinking akin to System 2, verifying step by step. This allows the models to improve their problem-solving abilities in handling complex issues by extending thinking time and analyzing the process step by step. This is another 'emergence' in the enhancement of model capabilities.
Figure 1. Illustration of o1 training
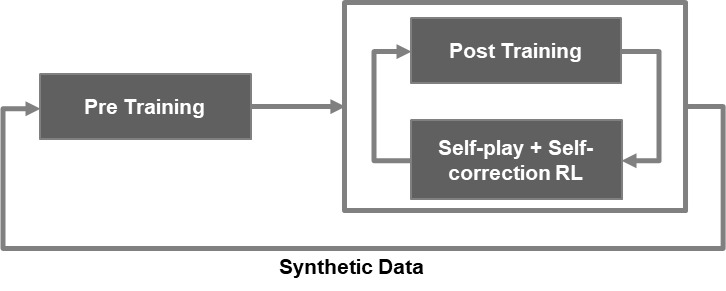
This diagram illustrates the training workflow with three main stages:
- Pre-Training: This is the initial stage where a model undergoes unsupervised learning on a large dataset to learn general representations or patterns.
- Post-Training: After pre-training, the model undergoes further refinement, possibly through supervised fine-tuning (SFT) or reinforced learning with human feedback (RLHF), where it adapts to more specific tasks or improves its performance on the primary objectives. Post-training could involve tuning on specific labeled data for better accuracy on the desired tasks. For o1, there are major breakthroughs in post-training, together with the next stage.
- Self-play + Self-correction Reinforcement Learning (RL): in this stage, the model engages in self-play or interacts within a simulated or real environment to improve its performance. Self-correction mechanisms are applied here to allow the model to identify and rectify its mistakes through reinforcement learning. This stage is iterative, as shown by the loop back to the pre-training/post-training stages, indicating continuous improvement through self-feedback and correction. Moreover, the post-training stage and self-play + self-correction RL stage generate massive synthetic data for pre-training, which is another crucial step for next generation foundation models.
Among them, RL (reinforcement learning) addresses is the lack of System 2 data for reasoning. It first enhances the model's reasoning ability in areas like coding and math, where 'standard answers' are relatively easier to obtain. Reasoning is not limited to specific fields (such as mathematics); instead, the aim is for the model to use similar thinking processes across a broader range of contexts.
Multi-step reasoning combined with search enhances the model's reasoning test time compute and its overall performance. To achieve this, OpenAI recruited a group of experts and rewrote the entire Data Infrastructure.
Lastly, synthetic data generated through RL is fed back into pretraining GPT-5. RL generates a large amount of failure data, which may not be of high enough quality to improve policies but is sufficient to be used for pretraining.
Figure 2. Demand for data is huge. Scale AI’s sales is surging

Scaling for RL and inference
Quote from Jim Fan: "The most important graph since Chinchilla. The previous generation of RLHF (Reinforcement Learning with Human Feedback) was to reach human-level performance, which would mark the end. This generation is Self-play for self-improvement’, and no ceiling is in sight. The compute power of RL has already surpassed that of pre-training.
Figure 3. Scaling of RL and inference, from OpenAI

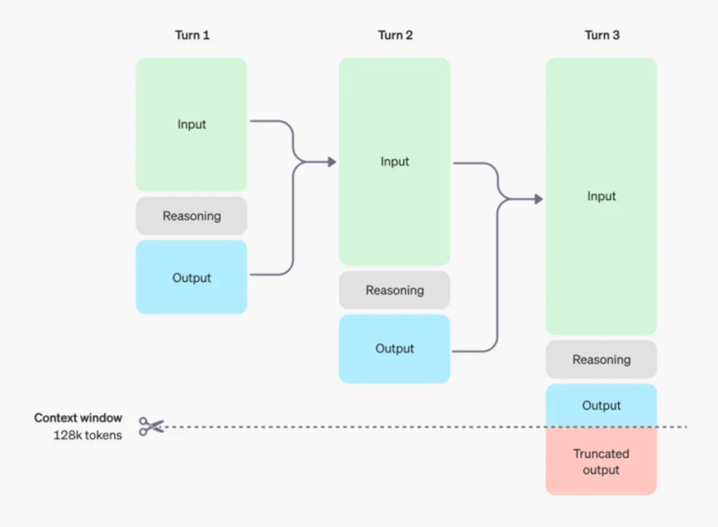
The scaling laws of RL are still in their early stages and have not yet fully converged. All methods are being experimented with, and we may not have reached or seen the RL equivalent of the GPT-3. In the past, RL used hundreds of GPUs, but now it uses tens of thousands. The scaling laws for reasoning imply that during both pre-training and reasoning, the context window must be very long. One key point is that it justifies the need for a long context. Previously, there were many debates about whether a long context was important.
Figure 4. Reasoning of o1, from OpenAI
NVIDIA's Future Monopoly in GPUs
This can be analyzed from both hardware and software perspectives.
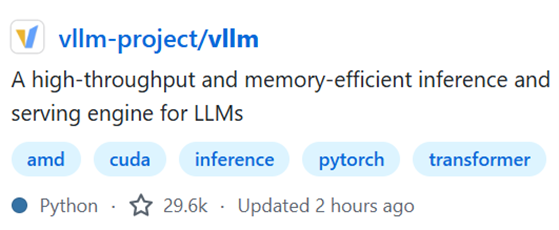
From a software standpoint, NVIDIA's monopoly through CUDA is gradually diminishing, especially as more models shift toward inference and reinforcement learning. Currently, three primary inference frameworks are gaining popularity: SGLang, VLLM, and TensorRT. TensorRT is favored for its good integration within NVIDIA's ecosystem, while SGLang and VLLM collaborate closely with OpenAI's framework. This shift reduces developers' dependency on CUDA, as C++ code can be cumbersome to migrate, particularly for younger developers who are more accustomed to modern programming languages.
Figure 3. SGLang, VLLM, and TensorRT. SGLANG and VLLM are Python based, rather than C++ based, which is programming language for CUDA.

In training, developers predominantly use DeepSpeed, Hugging Face, and other frameworks, particularly in academia. Although some NVIDIA tools (like Megatron LLM) may not offer a great user experience, the networking library NCCL's performance during training remains well-regarded. Therefore, developers still rely on NVIDIA's comprehensive framework during training, even as there is a conscious effort to expand their options.
Major companies such as AMD and Intel are increasing their support for third-party software to promote a more diverse software ecosystem. However, the rapid development of large models is primarily concentrated in a few companies like OpenAI and Google, which have the capability and motivation to develop and optimize their own software frameworks.
The paradigm shift from Pretrain-Inference to Pretrain Reinforcement Learning-Inference is advantageous for NVIDIA.
From a hardware perspective, NVIDIA currently appears to have a significant moat, particularly in scale-up strategies. The complexity of constructing ultra-large NVL domains such as NVL72, 288, 576, and even 1152 involves deep optimization of both hardware and software. By treating its hardware as a large unified memory, NVIDIA facilitates more efficient programming, which necessitates substantial software optimization support. Thus, scale-up may become NVIDIA's core competitive advantage, especially in handling long context processing and increasingly large model parameters.
From a hardware perspective, NVIDIA currently appears to have a significant moat, particularly in scale-up strategies. The complexity of constructing ultra-large NVL domains such as NVL72, 288, 576, and even 1152 involves deep optimization of both hardware and software. By treating its hardware as a large unified memory, NVIDIA facilitates more efficient programming, which necessitates substantial software optimization support. Thus, scale-up may become NVIDIA's core competitive advantage, especially in handling long context processing and increasingly large model parameters.
Figure 4. Nvidia DGX superpods

In terms of single-card performance, AMD's MI325 does not significantly differ from the B200. In scale-out scenarios, many companies are experimenting with their solutions based on Ethernet.
Many companies in Silicon Valley are trying to bypass NVIDIA's scale-up strategies. For example, Google employs a fully self-networked architecture; designs like the 3D Torus allow thousands of cards to connect without expensive switches. This approach has proven feasible, prompting companies to seek solutions independent of NVIDIA. Our recent investigations into various companies' ASIC developments reveal a collective desire to build proprietary systems.
Moreover, companies are hesitant to repeat last year’s reliance on NVIDIA's complete solutions. They aim to decouple their usage of NVIDIA's GPUs and software while maintaining autonomy in the overall network and system architecture.
In the AI sector, where market value is in the hundreds of billions, if the majority of revenues flow to NVIDIA, many enterprises will consider investing in self-developed chips and systems. Historically, Google has likely invested significantly in chip development, and it is merely a matter of time and resources. If new architectural paradigms emerge, companies may need to reconsider their competitive strategies against NVIDIA.
The Timeline for GPT-next?
We understand that Q2 of next year will be a critical period, particularly for new model releases. This model will be adjusted based on continuous feedback from the internal team's testing of new models. For instance, preliminary work will be done on functionality and alignment, and even before the model is fully developed, it may be offered for trial use. Users could compare different models, such as one being GPT-4 and another the new generation model, to assess their effectiveness.
Thus, rumors about GPT-5 often circulate because whenever a new version is released, the internal team conducts trials and disseminates news through Silicon Valley networks. For example, The Verge reported that if the new model is successfully trained, it will be referred to as GPT-5. The assessment of intermediate versions' effectiveness relies not only on benchmark tests but also on actual user feedback.
Rumors suggest that some individuals are already testing this new model, with larger trials expected by the end of the year. However, this does not imply that GPT-5 will officially launch by year-end, as extensive fine-tuning is still required. Particularly regarding reinforcement learning (RL), current development lacks a definitive endpoint; as long as adjustments continue, the model's capabilities can theoretically improve indefinitely. Thus, the complete final version is expected to be released in Q2 or Q3 of next year, though there may be interim versions released to generate additional interest.
The Ratio of GPU Utilization in RL
Figure 5. Referring to Jim Fan's graph, in reality, with the o1 generation, post-training compute power may have already surpassed pre-training, and it is still increasing.
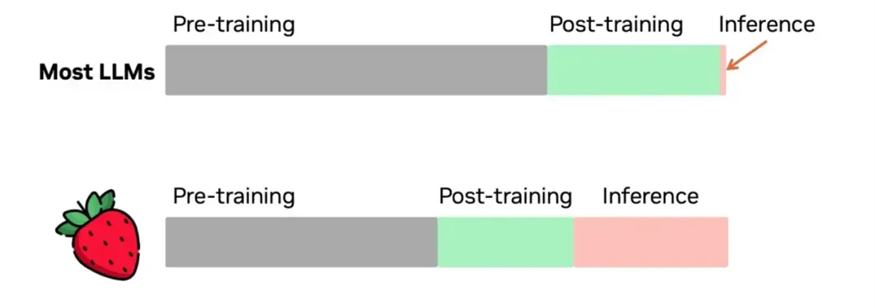
Regarding reinforcement learning (RL), there is currently no clear convergence standard, making it unclear how many GPUs are actually used. In the case of OpenAI, they have invested over $10 million in resources since initiating the Strawberry project about two years ago, and the team's demand for computing power has increased compared to the pre-training phase. Based on current trends, achieving a pre-training target of 10,000 GPUs may require an additional 10,000 to 15,000 GPUs for RL annually, and future demand could be even higher. However, as the model advances, the team may adjust their allocation of computing resources as needed, such as reclaiming some GPUs for pre-training during later training stages.
Currently, most of the GPUs are still used for training and inference, with a flexible overall computational power configuration, especially for inference cards. The demand for inference tasks is volatile; during low periods, tens of thousands of GPUs may be released at once for experimentation, but they are quickly needed back again.
The RL team currently possesses more resources, and the work on pretraining is aimed at enhancing model performance, particularly by extending the length of the context window and improving its quality. At the post-training stage, the effectiveness of Chain of Thought (COT) also relies on the quality of long sequence outputs. Therefore, it can be said that much of the pretraining effort serves the ultimate goals of RL. Overall, computational power plays a particularly important role in this process.
The RL team currently possesses more resources, and the work on pretraining is aimed at enhancing model performance, particularly by extending the length of the context window and improving its quality. At the post-training stage, the effectiveness of Chain of Thought (COT) also relies on the quality of long sequence outputs. Therefore, it can be said that much of the pretraining effort serves the ultimate goals of RL. Overall, computational power plays a particularly important role in this process.
On Enhancements in CoT and Industry Attitudes
The team at OpenAI is certainly optimistic about this direction, and internal investments reflect this attitude. However, there is no clear consensus on whether such extended thinking time is truly necessary. In contrast, Google may adopt a more conservative stance due to the larger number of individuals involved in RL internally, who hold differing viewpoints. They argue that performance enhancement does not necessarily depend on such long thinking times; there may be other RL methods that can achieve similar results.
There is general agreement on improving model performance through post-training and RL. Moreover, another key purpose of post-training and RL is to provide sufficient synthetic data to support the pretraining of the next-generation models. This point is unanimously recognized.
However, opinions diverge on whether it is necessary to sacrifice several seconds of inference time to achieve performance improvements, as suggested by OpenAI. Sometimes, sacrificing inference time may lead to unstable results or even errors, which can be frustrating. Therefore, while there is broad consensus on the need to sacrifice inference time for model performance gains, the specific amount of time to sacrifice remains an unresolved question without a clear formula.
On the Bottleneck of Synthetic Data
We believe that this field is indeed a frontier of research. What defines a research frontier? Here, the answers are not clear-cut. With the enhancement of foundational models, some emergent capabilities have indeed arisen. If a model does not reach the level of GPT-4o, the results obtained during synthetic data generation are often fraught with errors. However, once a model achieves the capabilities of GPT-4o, its effectiveness in generating synthetic data can significantly improve.
Currently, it appears that the use of synthetic data in post-training and later-stage pre-training may constitute around 95% of the data. In early pretraining, there does not seem to be a trend of large-scale synthetic data usage. This could be an important research point for the future. If models like Orion ultimately succeed, the development of synthetic data will likely continue as currently anticipated.
However, it seems that relying solely on multimodal approaches cannot significantly enhance the usability of foundational models; ultimately, there is still a need to depend on real data to generate a large volume of inference data. On the other hand, the increase in computational power allows for more experiments, potentially enabling us to resolve these issues more quickly.
Compute Use Cases Beyond Model Training
The situation is as follows:
- Meta, which uses GPUs for recommendations and may require 200,000 to 300,000 graphics cards, not all algorithms utilize GPUs, as the transformation is still underway.
- Google previously utilized AI to drive internal scenarios primarily using BERT algorithms with smaller inference clusters. They are currently transitioning to larger cluster demands.
- Meanwhile, many companies are still trying to leverage AI and generative AI to transform internal scenarios.
Figure 6. Nvidia H100 shipment in 2023. Meta is the largest customer.
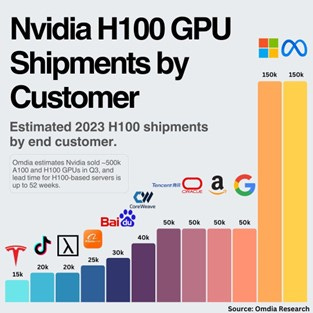
Additionally, OpenAI's situation is crucial. They expect revenue to reach $11.9 billion next year, with computing costs exceeding $4 billion, which translates to approximately 200,000 to 300,000 H-series cards needed. OpenAI's inference demand for GPUs has become relatively significant with the application of GPT. Furthermore, we are closely monitoring GPT-5 and OpenAI's other projects, especially since breakthroughs in coding and other application areas could generate substantial demand.
Progress in AI Coding
Our research indicates that the O1 model is still relatively new and currently available only in a preview version. Implementing functionalities similar to those of Cursor—a popular tool in the United States—does not appear to be particularly challenging. Any company integrating O1 could potentially achieve Cursor's current capabilities without significant difficulty. The primary requirement would be developing an integrated development environment (IDE) and programming tools, as the underlying algorithms are not overly complex.
However, it's important to note that O1 is still in its preview phase and not fully trained. Additionally, there is ongoing development of the O2 model and potential future integrations of GPT-5 with O1. These advancements theoretically promise further enhancements in programming capabilities. We are closely monitoring developments in this field, as it remains an area of active exploration.
SaaS + AI
Much of the automation in workflows can indeed be achieved through AI. The rapid growth of companies like Accenture, IBM, and Palantir has largely been driven by a surge in market demand for AI. Many traditional software service companies, especially those focused on outsourcing, have a significant proportion of labor costs in their cost structure.
For instance, Accenture is one of the world's largest consulting firms and has invested heavily in software development. With the advancement of AI, many positions may be automated, thereby enhancing work efficiency. At the same time, these Business Process Outsourcing (BPO) or IT service companies have the opportunity to automate processes through AI, transforming into more efficient operational entities.
Traditionally, these outsourcing companies employ a large number of software engineers tasked with writing various codes. In the future, these roles may be replaced by AI or improved through standardized processes to enhance efficiency. Particularly in consulting firms like the Big Four accounting firms and McKinsey, collaborations with companies like OpenAI are already underway to explore automation of various workflows.
Furthermore, market trends indicate a rise in the "Software as a Service" (SaaS) model and the "Service as Software" model, where companies pay based on the effectiveness of software usage. This market may see significant growth, particularly in countries like India and the Philippines, where millions are employed in outsourcing jobs that may also be at risk of being replaced by AI in the future.
Investigation of Current Computing Power Shortages
Keep reading with a 7-day free trial
Subscribe to FundamentalBottom to keep reading this post and get 7 days of free access to the full post archives.