


Deep|Two Key Beneficiaries: Why We Think 3D Torus Architecture is Critical to ASIC
Why I Bought These Two Stock During This Deepseek-induced Market Downturn

In our previous article on DeepSeek, we discussed how ASICs could benefit from lower inference costs and smaller distilled models. Now, let's explore why the 3D Torus architecture and its associated companies might emerge as the hidden winners in the GPU vs. ASIC battle.
In the era of artificial intelligence (AI), computing hardware such as Nvidia GPUs, TPUs, and custom AI ASICs play a fundamental role in training and inference workloads. However, as AI models continue to scale in complexity—requiring trillions of parameters and immense computational power—the efficiency of these hardware accelerators is increasingly bottlenecked by networking technology. Modern AI training and inference workloads often require distributed computing across multiple GPUs or custom accelerators. Therefore, the interconnects between compute nodes, the data transfer speeds, and the overall networking architecture are crucial in determining the performance and scalability of AI systems. This article explores why networking technology is indispensable to AI hardware and how advancements in networking shape the future of AI computing.

Introduction to Scale up and scale out (you may skip this part if you are already familiar with the concepts)
AI workloads can be expanded using two primary approaches: scale-up and scale-out.
Scale-Up (Vertical Scaling within one node): This involves increasing the power of a single node by upgrading its processors, memory, and interconnects. For example, using high-performance GPUs with increased memory capacity and faster interconnects like NVLink helps accelerate AI workloads within a single system. NVL72 GB200/300 is currently leading this field.
Scale-Out (Horizontal Scaling beyond one node): This involves distributing workloads across multiple nodes connected via high-speed networks. Technologies like InfiniBand and RoCE (RDMA over Converged Ethernet) advancements facilitate distributed AI training across GPU clusters, allowing larger models to be trained efficiently.
Why scale up is more critical in the battle of Nvidia GPU v.s. ASICs
As we discussed above, Scale-out involves distributing workloads across multiple nodes, typically using Ethernet or InfiniBand (IB) for connectivity. Scale-up, on the other hand, focuses on maximizing the performance within a single node or a tightly integrated cluster, often requiring high-bandwidth, low-latency interconnects like NVLink. Both approaches are vital, but scale-up is crucial when you're dealing with AI models that need extensive data sharing, synchronization, and communication between components within a single system.
Ethernet is Sufficient for Scale-Out: The Role of Broadcom and Other Players
In scale-out scenarios, where workloads are distributed across multiple servers or racks, Ethernet has made significant strides. Companies like Broadcom provide high-quality Ethernet switches that enable efficient data transfer between nodes.
InfiniBand is traditionally known for lower latency and higher bandwidth, but Ethernet has been closing the gap, making it a viable alternative in many scenarios, particularly for inference and less communication-intensive tasks.
Scale-Up Depends on NVLink: NVIDIA’s Key Advantage
The bottleneck in AI workloads often occurs within nodes, where GPUs need to exchange large amounts of data quickly. This is where scale-up networking is critical.
NVLink offers significantly higher bandwidth and lower latency compared to traditional PCIe connections, enabling GPUs to communicate directly with each other at very high speeds.
NVLink is unique to NVIDIA, and it provides a critical performance boost in data-intensive tasks like AI training, where GPUs need to share parameters, gradients, and activations rapidly and efficiently.
ASICs and other specialized chips don't currently have an equivalent technology. They can compete on specific tasks but struggle to match the intra-node communication efficiency provided by NVLink.
NVSwitch further enhances NVIDIA’s moat by extending NVLink’s high-speed, low-latency connectivity beyond point-to-point GPU communication, enabling fully connected GPU clusters within a node. Unlike traditional PCIe or even direct NVLink connections, NVSwitch acts as a centralized, high-bandwidth fabric that allows all GPUs in a system to communicate simultaneously at full bandwidth, significantly reducing communication bottlenecks in large AI training workloads. No other competitor, including ASICs, has a comparable intra-node switching solution, making NVSwitch a key differentiator that strengthens NVIDIA’s dominance in high-performance AI computing.
With NVSwitch, Nvidia is able to achieve a full mesh networking architecture with all-to-all communication. NVSwitch acts as a crossbar switch, allowing any GPU to communicate with any other GPU in the system with minimal latency, and every GPU is directly connected to every other GPU using NVLink. Therefore, in NVL72, 72 GPU can be viewed as ONE GPU when being programmed, which is critical for today’s giant models and complex test time compute inference.
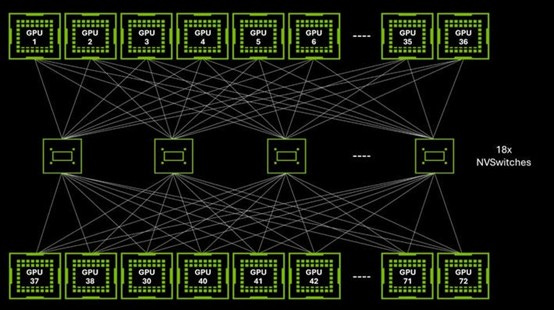

NVLink and NVSwitch enabled GB200 super rack
UALink might struggle to keep up with NVLink as expected.
In May 2024, industry leaders including AMD, Broadcom, Cisco, Google, Hewlett Packard Enterprise, Intel, Meta, and Microsoft announced the formation of the Ultra Accelerator Link (UALink) Promoter Group. This consortium aims to develop an open industry standard for high-speed, low-latency communication between AI accelerators in data centers. The initial UALink 1.0 specification, expected in the third quarter of 2024, plans to connect up to 1,024 accelerators within an AI computing pod, facilitating direct memory operations between GPUs.
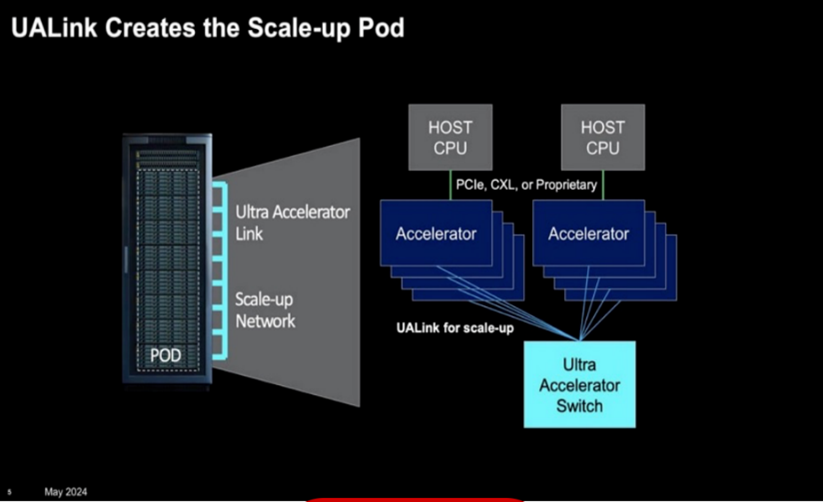
However, UALink faces significant challenges in competing with NVIDIA's established NVLink technology. NVIDIA's NVLink, especially when combined with NVSwitch, currently dominates the market by providing high-bandwidth, low-latency interconnects tailored for large-scale AI workloads. Broadcom's full commitment is crucial for UALink's success, as Broadcom's expertise in high-speed interconnects and switches is essential to develop a competitive alternative. Without Broadcom's active involvement, UALink may struggle to match the performance and adoption rate of NVLink, potentially hindering its ability to establish itself as a viable open standard in the AI accelerator interconnect market.
3D Torus: The Only Viable Alternative to NVLink
We believe 3D Torus networking has significant growth potential and will be widely adopted by cloud providers developing their own ASICs to reduce reliance on switch vendors. It also stands as the only viable solution for scaling up a single ASIC node, given the absence of switch technology comparable to NVSwitch.
In the next section, we will discuss the technology in details and highlight two stocks poised....
Keep reading with a 7-day free trial
Subscribe to FundamentalBottom to keep reading this post and get 7 days of free access to the full post archives.