
Deep|Snowflake: Fundamental Bottom?
Exploring the Potential of New Products in Driving Snowflake's Growth

Snowflake's Shocking News and CEO Change
On February 28, 2024, Snowflake released its fiscal fourth-quarter financial report, providing embarrassing full-year guidance and delivering another piece of news that shocked the U.S. Data Infra industry.
Frank Slootman, one of the most legendary CEOs in U.S. software history, announced his resignation from the position of Snowflake's CEO. The new CEO is Sridhar Ramaswamy, the Indian-born founder of Neeva. Sridhar joined the company after selling Neeva to Snowflake in May of the previous year and served as Snowflake's AI SVP, responsible for all new AI businesses. In less than a year, he went from being the founder of an acquired company to the new CEO of the parent company.
Snowflake CFO Michael Scarpelli mentioned in an investor communication a week after the financial report, "I didn't know about Frank's resignation until Tuesday (the financial report was on Wednesday)," "but as Frank and the board spent more time with Sridhar over the past year, we felt he might become Frank's successor." Scarpelli is Frank's old friend, and the two were a golden partnership at ServiceNow before joining Snowflake together. Outside of work, they also maintain a good personal relationship, both residing in Bozeman, Montana. Scarpelli might have been as shocked as we were.
Snowflake's angel investor and first CEO, Mike Speiser, later spoke about Frank's departure:
When Mike Speiser founded Snowflake with the company's two founders, he agreed on when he would step down, "when a product is delivered."
After Mike Speiser stepped down as the company's CEO, he let Microsoft's Bob Muglia take over and mentioned that this was a "clear upgrade." The goal during this period was to bring the product to market and establish a business model.
Later, the board realized that going public and scaling up would be the next big challenge, so they brought in Frank Slootman. Frank could keep the entire company in a state of high intensity and urgency, accelerating business growth and eventually leading to an IPO.
Mike Speiser and Frank Slootman also believed that Sridhar would be the most suitable leader for Snowflake in the next LLM era.
In the next big era of Data Infra, the LLM era, Frank may no longer be the most suitable CEO for Snowflake. This also made Mike Speiser, who had always achieved great results with each leadership change, sigh that Sridhar might be more suitable for the next stage's mission.
Sridhar later mentioned that in addition to Snowflake, the three major cloud vendors also invited him to be their AI leader, but he ultimately chose Snowflake. Sridhar is a rare talent with a combination of Database, LLM, and management skills. He has a PhD in databases and, as the "King of Google Ads," managed a huge team of over 10,000 people at Google, helping Google catch up with Meta in recommendation algorithms and making outstanding contributions to maintaining Google's leadership in recommendation algorithms. He later founded the AI search company Neeva.
One can't help but sigh that Data Infra has also been quickly pushed to the eve of a decisive battle in the LLM era. Only companies that have felt the urgency of the impending war would make the management choose to replace Frank, a hero of the previous era.
This change may not only be Snowflake's choice but also a choice that many software companies must make. A CEO with an AI background can clearly know where to invest in AI, what products and technical capabilities need to be supplemented, and where to find the talent to operate this together.
Data Infra Can Only Make Money by Entering the Training Process
From the story that Data Infra would benefit, a narrative which became popular in the first quarter of last year, until now, the representative companies Snowflake and MongoDB have not clearly mentioned the proportion of AI revenue.
In its fiscal fourth-quarter 2023 financial report, MongoDB explained for the first time why traditional Data Infra companies have not yet made big money:
Data Infra will participate in three layers in the large model field: model training, fine-tuning, and inference.
MongoDB's existing technology stack is mainly related to the latter two layers (fine-tuning and inference), but from the current customer use cases, the vast majority of customers are still in the first layer (model training).
When customers enter the third layer (inference), MongoDB will receive a larger scale of AI revenue.
This is also the current business reality in the Data Infra field. Only the new generation of Data Infra companies involved in training technology stacks have made money in this field. These typical processes include ETL/feature engineering, data lakes, vector databases, training optimization frameworks, and lifecycle management and experiment tracking tools commonly used in traditional machine learning. For example, the new generation of tools such as Databricks, Pinecone, and China's Zilliz and Myscale have all earned their first pot of gold in AI training.
Figure 1. Relit Tech Stack Diagram
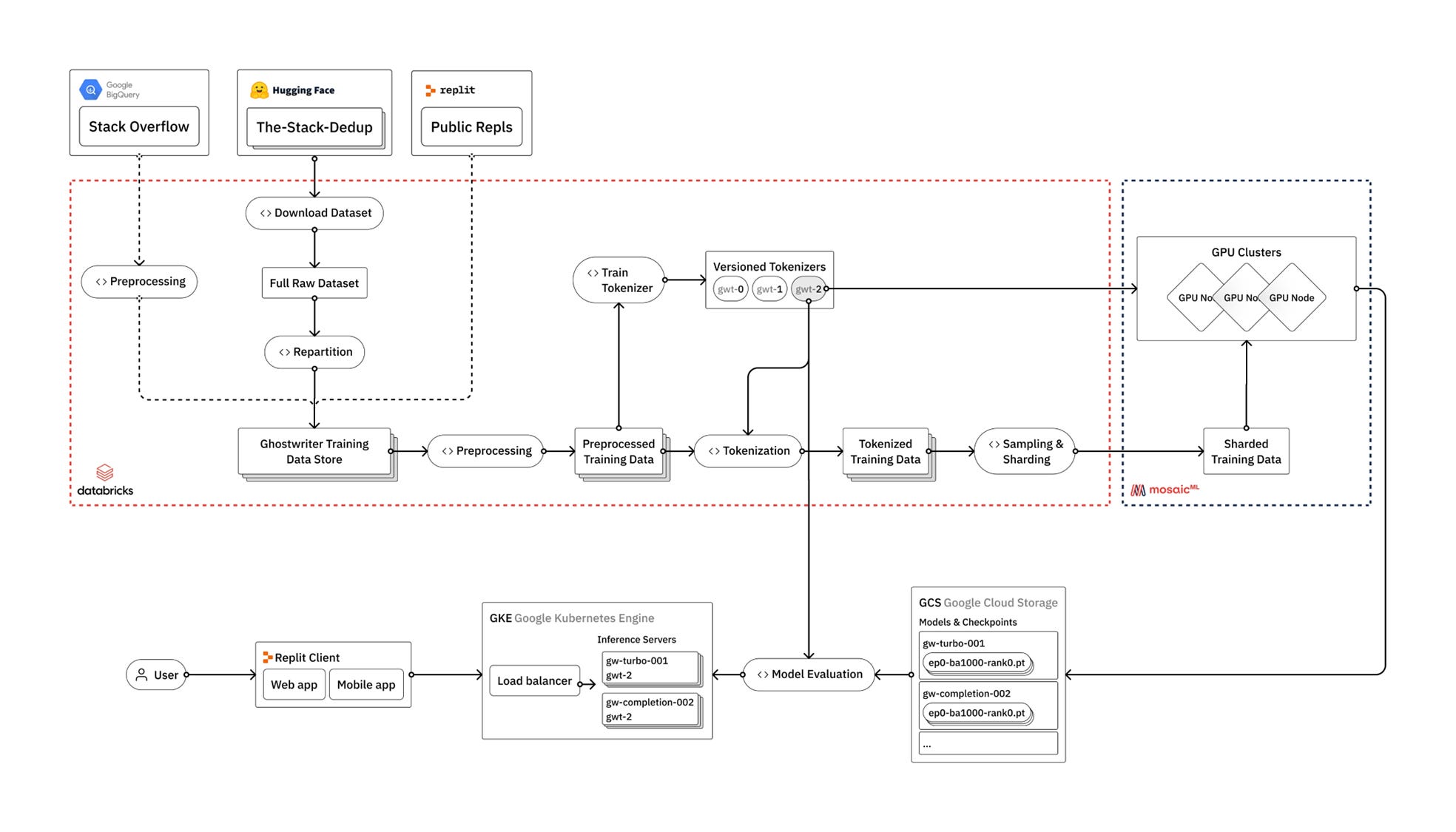
In the training process mentioned in the earliest Relit blog, the large model extensively used Databricks' technology stack and completed the model training process in cooperation with the infrastructure of the three major clouds.
Databricks' Success Story
Databricks is one of the most dazzling protagonists in the new generation of Data Infra.
In its newly disclosed business data:
Databricks' revenue reached $1.6 billion in 2023, a year-on-year increase of 55%.
It is expected to reach $2.6 billion in revenue in 2024, a year-on-year increase of 62%.
Its 2025 revenue is even planned to be close to $4 billion, still maintaining a 50% year-on-year growth.
Although its 2024 revenue of $2.6 billion is less than 70% of its competitor Snowflake's, its revenue model is different from Snowflake's. In addition to the SQL Serverless product that competes with Snowflake, which packages and sells cloud vendors' computing and storage businesses (earning money from software and computing storage premiums), most of the remaining products only sell software value (earning money from software).
It is more reasonable to compare the gross profit of the two companies, both excluding the pass-through revenue of cloud vendors. Databricks' gross profit is equivalent to ~80% of Snowflake's.
And next year, as Databricks' growth rate still maintains a high-speed growth of 50%, the gap will further narrow.
Compared to Databricks' current success, its development over the past ten years has not been smooth.
Databricks started with open-source Spark and later extended Spark to storage, creating the data lake blockbuster product Delta Lake. Looking at the development history of Spark, Spark has always been in fierce competition:
Spark is the earliest product in Databricks' entrepreneurial history and is still the company's most core product. It initially positioned itself as a support platform for machine learning and data engineering.
When Spark emerged, it could already cover almost all machine learning tasks before deep learning became popular. However, with the vigorous development of deep learning, Spark is no longer the most mainstream machine learning platform, and Tensorflow and later Pytorch have become more mainstream.
However, apart from becoming an independent machine learning platform, Spark dominates the data engineering field and is the most mainstream ETL tool on the market. This also gave Databricks the key ticket to grab ETL/Feature Engineering in the era of large models.
Another blockbuster product, Delta Lake, has also made it the largest commercial data lake service provider:
When processing machine learning data, a large amount of unstructured data is already required, and data lakes have become the most ideal and cost-effective storage method.
However, for a long time, the concept of a data lake was difficult for the procurement decision-maker - the company's CTO to understand, and it formed the perception of being difficult to build and maintain.
As Delta Lake became closed-source, open-source Open Format products such as Iceberg and Hudi later caught up. This ultimately led Delta Lake to open up open-source products and begin supporting external formats in Delta Lake 3.0.
During the same period of development, Snowflake, which was founded at almost the same time as Databricks, quickly opened up the gap with Databricks in terms of scale and growth rate due to its more understandable data warehouse concept and larger market space, making Databricks seem lackluster at one point.
To attack the "lucrative" data warehouse business, Databricks proposed the Lakehouse concept, an integrated product that can handle both lake and warehouse workloads. Compared to Snowflake, Databricks' SQL business in Lakehouse also has its characteristics:
Because it supports the Open Format of the lake, data does not need to be converted into a proprietary format of the data warehouse during the process of entering the data warehouse for computing. This saves customers storage costs (no need to prepare a copy of the same data for both the data lake and data warehouse) and additional Data Loading costs brought about by transmission.
At the same time, Databricks also gives customers greater autonomy, allowing them to use the computing and storage services they purchase from the three major clouds. This makes it particularly friendly to ultra-large customers (because of the large scale of customers, ultra-large customers can get very low discounts from the three major clouds).
This was accompanied by a crazy publicity offensive, which, while saving certain costs, also appropriately confused the different charging calibers of the two. It compared the fully-managed products of Snowflake without adding storage, computing, and Data Loading costs and cooperated with exaggerated claims, such as the slogan "we are 10 times cheaper than Snowflake" that has always been touted.
However, in the end, there are still many feature optimizations in the data warehouse field, such as the situation where various complex joins occur simultaneously. Excluding the differences in caliber mentioned above, Databricks SQL, which lacks innate skills in data warehouses, still has a substantial difference in cost-effectiveness from Snowflake in complex scenarios with large computing volumes.
Databricks' development has experienced several ups and downs, but it finally pulled through. The Spark and Lakehouse products it has been promoting have become the weapons for attacking the era of large models:
At the current stage of technology stack requirements, the completeness of platform functions (being able to achieve goals end-to-end) is more important than the superiority of a single function.
The era of large models presents an explosive growth in the processing of unstructured data. Delta Lake + Databricks Spark, as the golden partners for unstructured data processing, have become the mainstream technology stack and occupy a large amount of ETL/Feature Engineering workloads on the market.
By continuing to extend outward along Spark, Databricks began to support the Iceberg Open Format. This also laid the foundation for Databricks to attract more unstructured data and build a complete Lakehouse solution.
At the same time, Databricks launched the Databricks Spark Container Service and, after acquiring MosaicML, became another full-stack large model training platform after the three major clouds and NVIDIA, almost completing the last piece of the puzzle.
The debate over the Lakehouse route came to an end when Snowflake began to fully embrace the Open Format in 2024 and allowed customers to use their own storage. Lakehouse became the mainstream of the big data era. Whether entering from the lake or from the warehouse, it will eventually become a Lakehouse solution.
Snowflake's Catch-up Plan
Unlike Databricks, which has always focused on unstructured data and machine learning work, Snowflake's route is more divergent, and it has not invested much effort in the machine learning field in the middle.
Snowflake's founder, Benoit Dageville, has been in charge of Snowflake's technical route. Before 2023, the focus was on Unistore and Snowpark. Let's talk about Unistore first:
Unistore is an HTAP-like product with a KV Store design at the bottom. Benoit hopes that this product can help Snowflake expand market opportunities in the larger database field (OLTP). However, because of its KV Store design, its direction still cannot directly compete with mainstream OLTPs such as Oracle. It is more suitable as a solution adopted by companies that primarily use OLAP with OLTP as a supplement.
The technical difficulty of implementing Unistore is also relatively high. It is not in the data warehouse field where Snowflake originated, and it has extremely high requirements for latency and stability. At the same time, HTAP is also a new technical solution, and pioneers in the HTAP field have always hit a wall, making it difficult to say that HTAP has succeeded in its business model.
Compared to Unistore, the narrative of Snowpark is more straightforward:
Snowpark has a more coherent product logic. When customers transfer data into Snowflake, they need to perform ETL processing. In the past, the mainstream processing methods were Open-source Spark and Databricks Spark. Now, using Snowflake's native ETL tool saves transmission costs and has no functional difference. Customers switching to Snowpark for cost-effectiveness should be a natural choice.
Compared to Open-source Spark (more sold as the EMR product among AWS customers), Snowpark's cost-effectiveness advantage is very obvious. However, compared to the optimized commercial product Databricks Spark, Snowpark has certain advantages more in data processing for customers already using Snowflake products.
Although Snowpark can quickly catch up with the Data Engineering workload and its technical barriers are not high, there is still a lot of work to be done in the machine learning field, especially in the face of Spark's open-source advantages. Snowpark is more focused on providing machine learning capabilities for specific traditional industries.
After Snowpark was commercialized at the end of 2022, its revenue scale at the end of 2024 should reach 130-140mn ARR according to the company's description, roughly 5-10% of Databricks' ETL ARR, with a doubling year-on-year growth. Compared to the Databricks SQL product launched to compete with Snowflake, its scale is about 1/3 of Databricks SQL and was launched a whole year later than Databricks SQL.
The Snowpark product also reserves a ticket for Snowflake to the era of large models. Snowflake's future large model support products will also be built around Snowpark:
Snowpark brings Snowflake the ability to process unstructured data. In the era of large models, it can handle the demands of ETL and Feature Engineering.
By continuing to extend outward through Snowpark, Snowflake began to support the Iceberg Open Format, which also laid the foundation for Snowflake to attract more unstructured data and build a complete Lakehouse solution.
At the same time, Snowflake launched the Snowpark Container Service, which has become the focus of Snowflake's future work, GPU workloads for Snowflake. It allows customers to fine-tune and deploy models in the Container Service.
After Sridhar joined Snowflake, he also focused his efforts on the new product Cortex:
Cortex LLM Inference brings Snowflake many large model partners and allows LLM queries to be completed within Snowflake.
Cortex Search may be even more critical, carrying Snowflake's hope of achieving a RAG solution in the future. Sridhar is integrating the RAG-Vector Search solution used by Neeva in the past into Cortex, which will soon bring vector storage and processing capabilities to Snowflake. In the future, it can also support more Container Service customers, allowing customers to directly deploy and infer models in the Container Service.
Cortex Analyst is a longer-term goal. At this year's Developer Day, Snowflake showcased its Cortex Analyst and defined it as a Data Agent. Its importance also surpasses the previously discussed Text2Sql.
Sridhar is very clear about what Snowflake lacks and knows how much effort to invest. This can be seen from Snowflake poaching the founder of DeepSpeed and its core team:
Snowflake's CFO mentioned in a subsequent communication that the five people poached from DeepSpeed required an annual cost of 20mn USD, "which is very surprising, they are too expensive and too excellent."
But Sridhar clearly knows that in order to become an end-to-end training/inference technology stack, Snowflake must also be able to find excellent targets like MosaicML. If it cannot acquire, then directly poach people. The DeepSpeed team is almost the best choice, and it is also the most popular large model training/inference framework.
This was almost unimaginable during Frank's era. High costs and uses that were difficult for the company's "old guard" to understand could only be achieved under the top-down push of the new CEO.
After changing CEOs, Snowflake has also made an all-in AI stance, with all products focusing on Data Engineering and its derived AI.
There may be positive changes within the company:
Although Frank Slootman is a legendary CEO in Silicon Valley, his focus is more on sales management and rarely on product development planning. All products are basically the responsibility of Benoit Dageville. This may also cause a disconnect between products and customer needs.
Because Sridhar understands technology, he began to be responsible for coordinating products, R&D, and sales,and filled the organization with a positive atmosphere of fighting against Databricks.
In addition, Sridhar has focused on the new products that can bring in revenue, mainly including Snowpark and Iceberg Data Lake.
MongoDB's RAG Story
Unlike Databricks and Snowflake, MongoDB is not on the analytics side. Its products focus more on supporting business data flow and storage, OLTP.
In early 2023, MongoDB was once the top 1 pick in Data Infra. The market logic at that time was:
MongoDB developed from a document database and can first not consider too much about the data structure (whether structured, unstructured, semi-structured, etc.). Data can be put in first and then processed, which has very high ease of use.
Large model training and inference will use a lot of unstructured data, and MongoDB's main products are for storing, reading, writing, and querying semi-structured and unstructured data.
On the training side, MongoDB may be used as an unstructured data storage medium, which may further increase MongoDB's importance in the customer's technology stack.
MongoDB has the opportunity to create its own vector database and enter the model inference side.
More LLM applications also mean more APPs. They may not necessarily use MDB in the LLM process, but they still need to store Chatbot chat records and traditional OLTP loads through MongoDB.
MongoDB was also very cooperative in mentioning in the first quarter of 2023 that it had 200 new customers who were AI customers, including well-known companies such as Hugging Face and Tekion. However, in subsequent quarters, MongoDB no longer disclosed its AI customer information.
MongoDB's main focus is on the inference side, which is also mentioned in its latest quarter that the large model scenario is still on the training side and has not yet entered the inference side, resulting in its revenue contribution not being significant.
Examining MongoDB's opportunities on the inference side:
Compared to the previous two companies' inference side, which is more at the Data Application and API level, MongoDB can provide services to end users, which is inseparable from its OLTP positioning.
MongoDB's Atlas Vector Search service was the first to provide GA vector search functionality and began commercialization in early 2024.
For its existing customers, the traditional technology stack may be more trustworthy, especially when RAG requirements are not yet large-scale, MongoDB's vector search service may already meet the requirements.
However, compared to other RAG solutions, MongoDB is still in the early stage of RAG:
In scenarios with large data volumes and concurrency, MongoDB still lags behind AI-native vector databases (mainly because Mongo's accumulation in vectordb engine algorithms is still weaker than these professional vector databases, and as inference scenarios become widely promoted, data volumes will increase significantly, and considerations for engine capabilities will become more and more).
The new generation of RAG methods not only rely on the combination of Dense Embedding with vector databases but also have extremely high requirements for traditional BM25. In this regard, it may not be as good as Elastic's solution.
For MongoDB, there are still a large number of features that need to be caught up.
Comparison of Snowflake, Databricks, and MongoDB Products
We have listed the LLM progress of the three companies in the following charts. The first one is the training side.
Figure 2. LLM Training Tech Stack
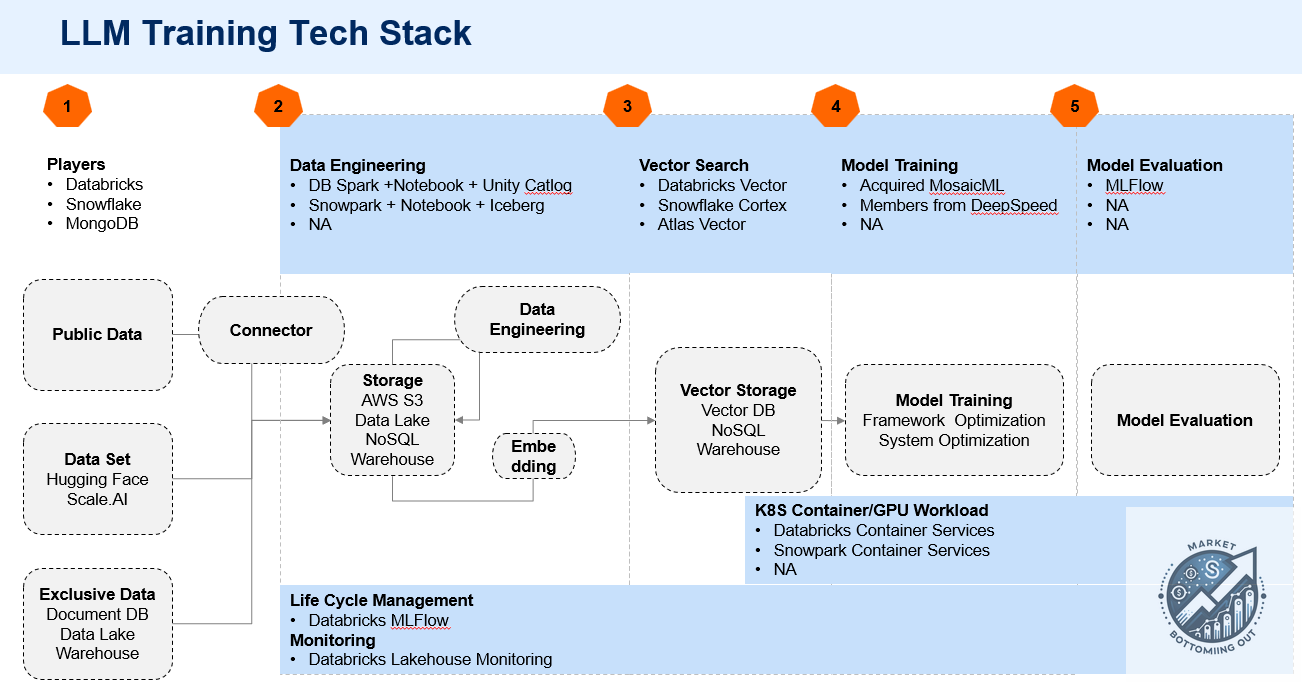
Databricks is a full-process training technology stack and completes the last link through MosaicML. However, it still has a certain gap compared to the public cloud in large model training.
Snowflake is in the process of patching, and there are still large gaps in notebooks, data lakes, model training optimization, and MLFlow. Currently, it is more about allowing customers to fine-tune in its Container Service.
MongoDB's focus is on the inference side and basically does not involve training.
Figure 3. LLM Inference Tech Stack
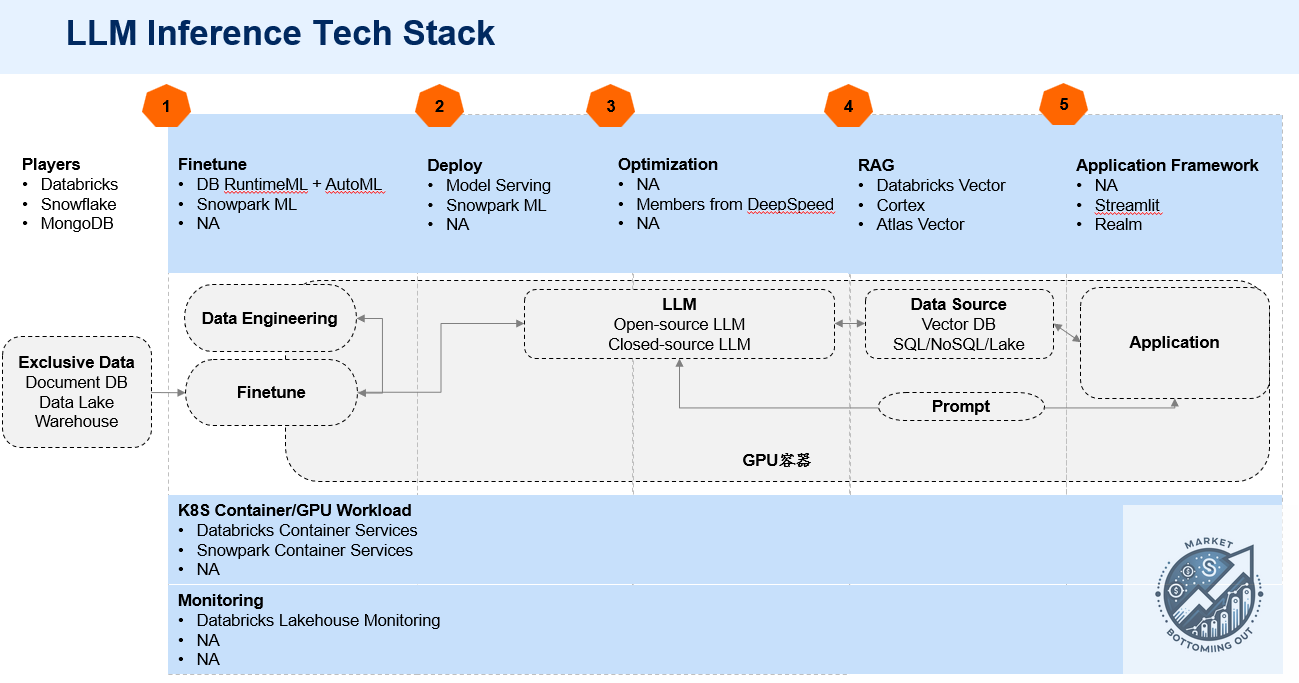
Databricks' RAG solution officially GA this year, just having the ability to infer in one-stop.
Snowflake's Snowpark ML and RAG solution also GA this year. In the future, it will support more inference of Data Applications deployed on the Container Service, which may be scenarios such as customer service chatbots and enterprise knowledge bases.
Although MongoDB is not involved in fine-tuning and containers, it focuses more on RAG solutions for end users, targeting a wider customer base.
Customers with leading technology are already adopting the LLM technology stack of the three major clouds and various AI-native platforms. The main incremental growth of the three companies in the future is still in traditional corporate scenarios:
For traditional companies, an end-to-end technology stack is very important. In the era of LLM talent scarcity, customers cannot establish the best LLM team. For the training/inference process, the simpler the better.
Traditional companies are also increasing their LLM budgets. This may be training their own open-source models for scenarios such as customer service, or purchasing other third-party software application solutions.
However, from a historical perspective, application solutions may initially provide their own built Data Infra, but as the ecosystem becomes connected, customers also use more of their own Data Infra to support all third-party solutions.
Snowflake's Fundamentals Have Bottomed Out (Model Derivation)
After talking so much about products and technology, let's return to financial models.
Keep reading with a 7-day free trial
Subscribe to FundaAI to keep reading this post and get 7 days of free access to the full post archives.